Unix_named_pipe
Unix Named Pipe
Pipe file system is one of the beatiful feature, which serves mutiple different purposes. The most amazing of them is IPC. Writing s local server(or process), which does time consuming job, can be communicated using unix pipe. So all the clients(or communicating process) will open up the named pipe,on which the server is listening and write onto that pipe without waiting for any ack back from the server. On the other hand, the server will gradually read each request one by one from the pipe and serve the requested job. That way the client process can asychronously do the work, without delegating the job in another thread.
In the following sections I will try to describe, how we can setup the link between two communicating process using unix named pipes.
Creating Pipe
Creating a pipe is fairly simple. From the shell we can use,
mknod /tmp/arijit_fifo c
or a little more handy way of doing this ,
mkfifo /tmp/arijit_fifo
From C/C++ program, we can achieve this by,
// S_FIFO -> This is the fifo file
// S_IRUSR -> Reading permission
// S_IWUSR -> Writing Permission.
// 0 -> Asking to ignore this parameter
int rc = mknod(fileName.c_str(),S_IFIFO | S_IRUSR | S_IWUSR, 0);
Now once this pipe creation is done, so we will go forward with reading from the file. Reading from the file completely(or in other words, tailing the file), is just like reading any other file.
while true
do
read line < $reader_pipe;
echo $line
done
Doing same from the C++
fstream fs;
fs.open(fileName.c_str(),fstream::app| fstream::in | fstream::out);
if(fs.is_open()){
fs<< "Writing into pipe" << endl;
fs.close();
}
Putting all the things together, I wrote a small server prograim using bash shell script, which is going to read from the pipe and just simple echo them and only on receiving “exit” the proggram exits. The code is as below,
#!/bin/bash
reader_pipe=/tmp/arijit_reader;
function init
{
if [[ ! -p $reader_pipe ]];
then
mkfifo $reader_pipe
echo "Pipe created"
fi
}
function reader
{
while true
do
read line < $reader_pipe;
echo $line
if [[ $line == "exit" ]];
then
break;
fi
done
}
I also wrote another C++ client code, which will open this pipe and write into this with tunable number of threads(tunable is coming as a part of the argumnet to program).
int threadHandler(int id)
{
string fileName("/tmp/arijit_reader");
int rc =
mknod(fileName.c_str(),S_IFIFO | S_IRUSR | S_IWUSR, 0);
// One can use pipe or pipe2 system call as well.
fstream fs;
fs.open(fileName.c_str(),fstream::app| fstream::in | fstream::out);
if(fs.is_open()){
for(int counter = 0; counter < 10000; ++counter) {
stringstream ss;
ss<< "From thread " << id << ":" << counter ;
fs << ss.str() << endl;
ss.flush(); // just to make sure we are flushing the data
//this_thread::sleep_for(chrono::duration<int,milli>(200));
}
fs.close();
} else {
cerr << "Unable to open the file" << endl;
return -1;
}
return 0;
}
int main(int argc, char **argv)
{
int counter = atoi(argv[1]);
vector<thread> tList;
for (int i = 0 ; i < counter; ++i ) {
tList.push_back(move(thread(threadHandler,i)));
}
for_each(tList.begin(), tList.end(), [](thread& t) {t.join();});
return 0;
}
Experimental Results:
If we gradually increase the number of threads, we will see the gradual increase in the load using htop utility on a terminal. Since each thread is writing 10k times, I assume it is a good load to test with.
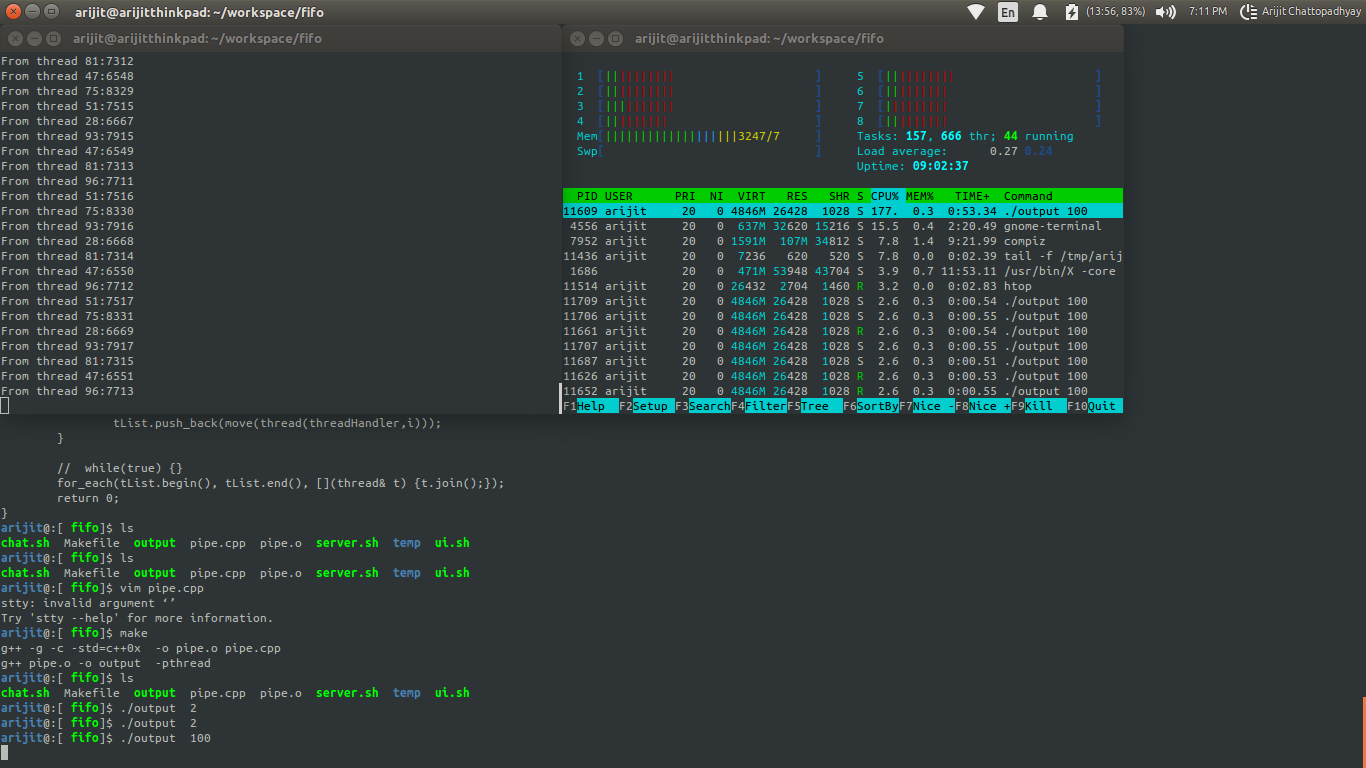 I was runnint this program in a laptop, with 8 Gigs of ram , 2.6Ghz i7 prorcessor with 8 HT cores(4 real cores), running ubuntu 14.04. Though this is entirly an io bound process, but I could see as I was increasing the number of threads, the shell server was starting to consuming more and more CPU cycles and the virtual memory usage by each thread in C++ program is aslo increased, keeping the cpu profile fairly constant, which is understandable as each writing thread is doing the same work. I was wondering what is causing the high cpu usage for the server program. The pipe.c source contains the answer. Overall the algorithm looks like
I was runnint this program in a laptop, with 8 Gigs of ram , 2.6Ghz i7 prorcessor with 8 HT cores(4 real cores), running ubuntu 14.04. Though this is entirly an io bound process, but I could see as I was increasing the number of threads, the shell server was starting to consuming more and more CPU cycles and the virtual memory usage by each thread in C++ program is aslo increased, keeping the cpu profile fairly constant, which is understandable as each writing thread is doing the same work. I was wondering what is causing the high cpu usage for the server program. The pipe.c source contains the answer. Overall the algorithm looks like
lock(pipeMutex)
read everything from the buffer
unlock(pipeMutex)
As the buffer is continuously growing by the enormous write from the writers, the reader is getting super saturated with reading and also this loop is getting executed more and more, which in turn causing more lock-unlock operations and these two are resulting high cpu usage.
After I increased the thread count to 1022, one thread was not able to open the pipe. All further increase of the number of threads, that failure increased fairly linearly. After little bit of investigation, I checked the limit using /proc/<pid>/limits in my ubuntu system and I found the max number of open file descriptor from a process allowed is 1024. With 1022 threads, we are going to open 1022+3 fd, which is exceeding the maximum permitted limit.
A Libevent based program to read from a file asynchronously
The nice things about this libevent based program is that, it never buffers anything.
#include <string>
#include <iostream>
#include <fcntl.h>
#include <event2/event.h>
#include <assert.h>
#include <unistd.h>
using namespace std;
void fifo_read_cb(evutil_socket_t fd, short event, void *arg)
{
const int buf_len = 1024;
char buffer[buf_len] = {0};
int rc = read(fd,buffer,buf_len-1);
cout << buffer;
}
int main()
{
int fifo_fd = open("myfifo",O_RDONLY| O_NONBLOCK,0);
if(fifo_fd < 0 ) {
cerr << "Unable to open the file" << endl;
}
struct event_base *base= event_base_new();;
assert(base != NULL && "base is null");
struct event *evfifo = event_new(base, fifo_fd,
EV_READ|EV_PERSIST,fifo_read_cb,NULL);
event_add(evfifo,NULL);
event_base_dispatch(base);
event_base_free(base);
close(fifo_fd);
return 0;
}